
TL;DR
- Open-Source Transcription Software: Convert speech to text with full accessibility to source code, allowing for customization, offline functionality, and cost-effective solutions.
- Amical: An advanced transcription software designed for productivity, offering context-aware formatting, offline AI models, and cloud-based options.
- Whisper: OpenAI's model for high-quality transcription with multi-language support, ideal for real-time transcription and integration.
- Vosk: Lightweight, offline transcription tool supporting over 20 languages, perfect for low-resource devices and privacy-focused use cases.
- Kaldi: Powerful toolkit for research and custom speech recognition models, offering flexibility and control over ASR pipelines.
Introduction to Transcription Software
You’ve recorded an important meeting, a podcast interview, or a lecture, but now you need a clean, searchable text version. Manually typing it all out can be slow, error-prone, and exhausting. That’s where transcription software steps in, converting your audio or video into accurate, readable text. These tools, powered by advanced machine learning models, can process speech from a variety of sources, handle different accents, and even manage multi-speaker recordings with impressive precision.
However, traditional transcription platforms are often locked behind subscriptions, rely heavily on cloud processing, and limit your control over data. This means your recordings are sent to remote servers, raising privacy concerns and making them less suitable for confidential material. Many also offer limited export options or lack flexibility for specialized workflows.
Open-source transcription software offers a compelling alternative. It’s transparent, customizable, and can be run fully offline, ensuring your sensitive recordings never leave your device. Developers can adapt the code to integrate with existing systems, add custom vocabularies, or fine-tune models for niche industries. Whether you need high-accuracy transcripts, multi-language support, or tailored formatting for research or production work, open-source transcription tools give you more freedom and control than proprietary options.
In this article, we’ll explore the 6 best open-source transcription tools of 2025, covering real-time and batch processing capabilities, offline performance, and integration potential, so you can choose the right solution for your workflow.
How to Choose the Right Open-Source Transcription Software
Every transcription tool comes with its own strengths and trade-offs. Some excel in real-time captioning, others in handling complex, multi-speaker recordings. Picking the right one depends entirely on your needs and environment. This guide will help you narrow it down, no need to download and test every tool yourself.
Define your use case
Start by clarifying what you’re transcribing. Are you a journalist turning interviews into publish-ready copy? Then, accuracy and speaker labeling might be your top priorities; tools like Whisper or Amical could be a fit. If you’re a developer building automated meeting summaries, API-friendly frameworks such as Kaldi or Vosk may be better suited. For students or researchers working offline, lightweight transcription software on macOS or iOS could be ideal for portability and privacy. Consider where your tool will run (desktop, mobile, server), your privacy requirements, the size of your audio library, and whether you need integration with editing suites or CMS platforms.
Key Factors to Evaluate
- Accuracy – Leading open-source tools like Whisper and DeepSpeech are trained on massive datasets, enabling them to handle varied accents, background noise, and domain-specific terminology.
- Latency – If you need near-instant transcription for captions or live streams, low-latency performance is essential. Whisper and Vosk offer strong edge performance, while batch transcription can trade speed for even higher accuracy.
- Language Support – Multilingual capabilities vary widely. Whisper supports dozens of languages out-of-the-box, while Kaldi and DeepSpeech can be extended with custom models.
- Offline Capability – For privacy and low-connectivity environments, offline processing is a must. Vosk, Whisper, and Kaldi can all run fully locally without sending data to the cloud.
- Ease of Integration – A well-documented API and flexible architecture matter if you’re embedding transcription into a larger system. Amical is known for its user-friendly interface, while Kaldi and Whisper offer deep customization potential.
- Community Support – Active projects mean faster bug fixes and feature updates. Whisper-based tools and Kaldi enjoy large, engaged developer communities.
Always test with your own audio
Transcription accuracy can vary depending on background noise, speaker accents, and recording equipment. Before committing to a tool, run it on real samples from your workflow to see how it performs.
Balance trade-offs
Some software, like Mozilla’s DeepSpeech, delivers high accuracy but requires more setup and computational resources. Others, such as Vosk or Amical, are designed for ease of deployment and faster integration, ideal for teams prioritizing speed and simplicity. Each tool brings its own strengths, so choose the best transcription software based on what matters most to your project: accuracy, speed, scalability, or ease of use.
Overview of the Best Open Source Transcription Software in 2025
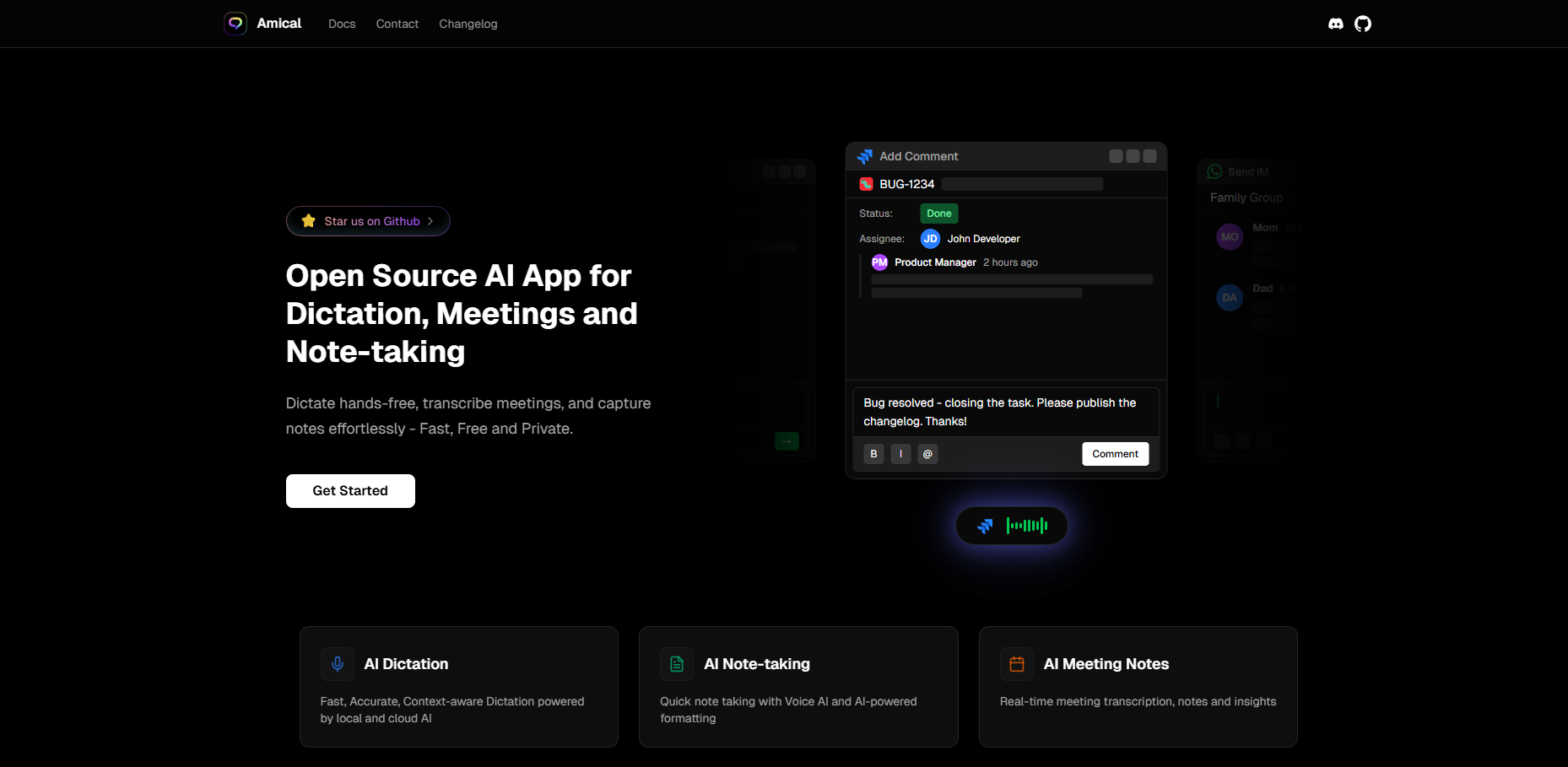
Amical is an open-source transcription and note-taking platform powered by generative AI, designed for users who want faster, smarter, and more context-aware voice input. Unlike traditional transcription software, Amical not only converts speech into text with exceptional accuracy but also adapts to the context of your application, formatting text appropriately for professional emails, casual social posts, or project updates.
Unlike Whisper, Vosk, or Kaldi, which are transcription models, Amical is a desktop application for Mac and Windows that integrates these models and provides dictation and meeting transcription features at the push of a button.
Built for Mac and Windows (with mobile support planned), Amical offers privacy-first transcription by allowing users to choose between local AI models for offline use or cloud-based models for advanced accuracy. This flexibility ensures both performance and data security. All these facilities rank it as one of the best transcription software that are currently emerging.
The picture below illustrates how Amical transcription is a more advanced option than native transcription tools for Mac and Windows.
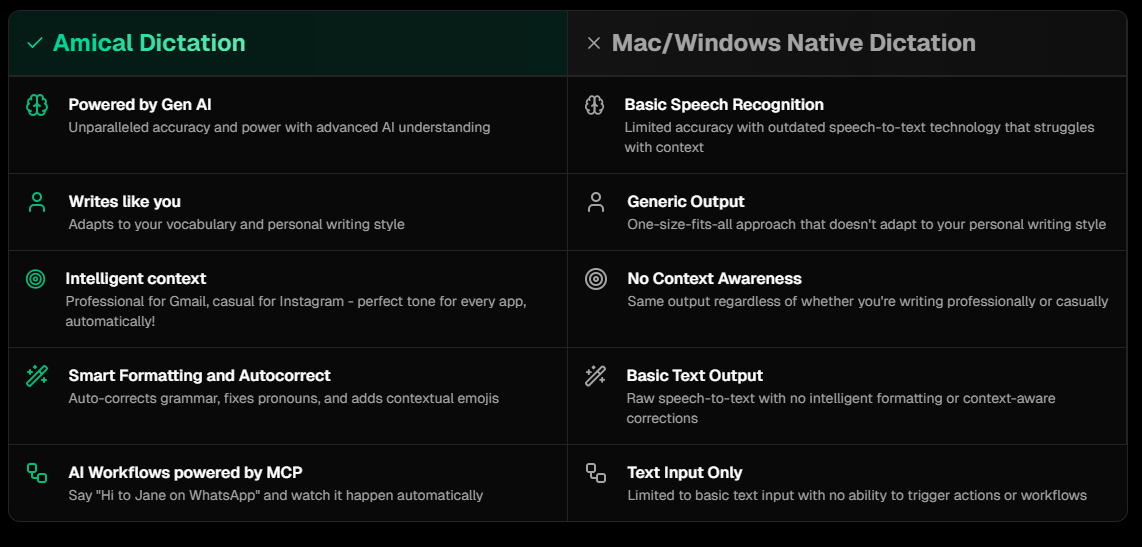
Features
- Context Awareness (Available): Recognizes context based on the apps being used in the background to customize transcription according to the use case.
- Note Taking (In Progress): Enables quick note creation using voice within the app.
- Meeting Transcription (Planned): Records live meetings using both microphone and system audio for seamless transcription.
- Automatic Meeting Notes (Planned): Generates structured meeting notes using transcriptions and predefined templates.
- Custom Hotkeys (In Progress): Let's you configure keyboard shortcuts for common transcription actions like start, stop, and commands.
- Desktop Widget (In Progress): Provides a floating, easily accessible widget to control transcription without leaving your workflow.
- Multi-Language Support (Available): Offers support for multiple languages and dialects for global usability.
- Custom Vocabulary (Available): Allows users to add custom terms such as names, technical jargon, or slang for improved accuracy.
- Automatic Vocabulary Learning (Planned): Dynamically learns new words based on usage patterns.
- Bring Your Own Key (Planned): Enables the use of your own API keys for AI models within the app.
- Bring Your Own Model (BYOM) (Planned): Allows you to point to any AI model within the app for custom processing.
Use Cases
- Email & Business Communication: Produce formal emails with correct structure instantly.
- Social Media Posts: Switch to an informal tone for Instagram or WhatsApp.
- Meetings & Team Collaboration: Record and transcribe discussions in real-time.
- Hands-Free Productivity: Execute commands, integrate workflows, and streamline multitasking.
- Accessibility: Assist users who prefer or need alternatives to typing.
Limitations
- Some Features Pending: Meeting notes, multi-language, and integrations are in development.
- Desktop-First: Mobile support is still planned.
- Hardware Requirements: Larger models (e.g., large-v2) in Whisper require more computational power, and users with less powerful hardware may experience slower transcription speeds or delays.
Vosk is a lightweight, open-source, offline speech recognition toolkit that supports over 20 languages and dialects. It simplifies automatic speech recognition (ASR) by offering pre-trained models and easy-to-use APIs across a wide range of platforms, including Android, iOS, Raspberry Pi, Windows, and Linux. Many transcription software cannot support such a wide range of platforms. It’s particularly well-suited for developers building voice-enabled applications without relying on cloud infrastructure or internet access.
Its installation is very easy, and it is ideal for both rapid prototyping and production use where privacy, speed, and low-resource requirements are key considerations.
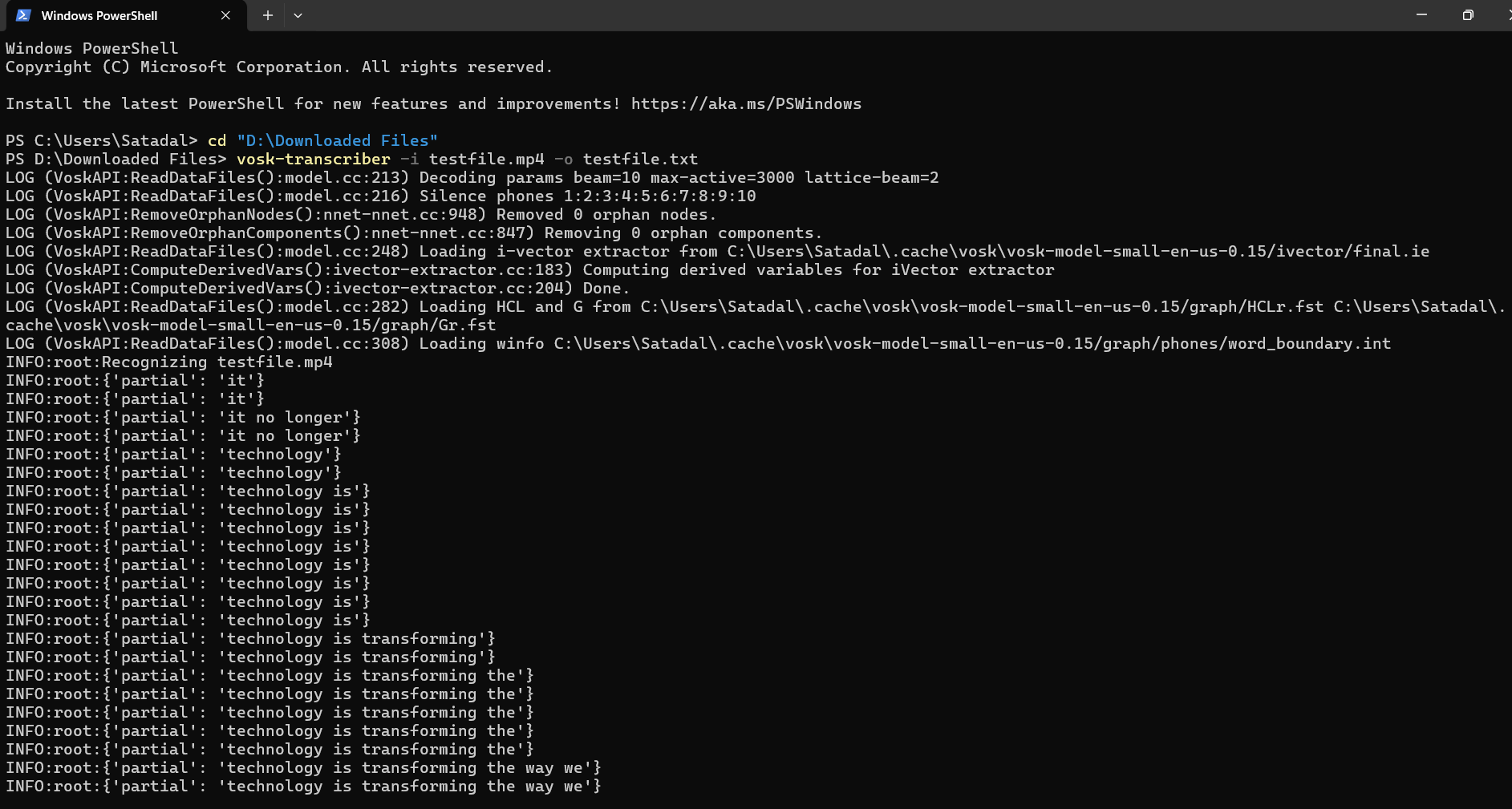
Below is a demonstration of how to use Vosk with a test file. Please note that you’ll need Python version 3.5 to 3.9 and FFmpeg installed on your device to run Vosk.
Features
-
Multilingual Support: Pre-trained models available for 20+ languages, including English (and Indian English), French, Hindi, Arabic, Chinese, Japanese, and more.
-
Offline Functionality: Fully operable without internet, making it suitable for privacy-sensitive or remote environments.
While Vosk performs excellently on low-resource devices, its accuracy may not match that of Whisper or other transformer-based models in highly complex or noisy environments.
-
Small Model Size: Compact models (~50MB) that run even on low-power devices like Raspberry Pi. However, they are less accurate than larger models.
-
Streaming API: Enables real-time transcription with zero latency, suitable for live applications.
-
Multi-language Bindings: Supports Python, Java, Node.js, C++, C#, Go, Rust, and more.
-
Custom Vocabulary & Lexicon Tuning: Allows developers to tweak language models at runtime for better accuracy in specific domains.
-
Ease of Use: Simple setup, CLI tools, and clear API design help developers integrate ASR quickly.
Use Cases
- Voice-Activated Assistants: Used in smart home devices and embedded systems for accurate offline voice command processing.
- Subtitling & Media Transcription: Powers subtitle generation tools like SubtitleEdit and transcribes lectures, podcasts, and interviews.
- Language Learning Apps: Enables real-time pronunciation feedback and interactive speech exercises.
- Medical & Legal Transcription: Supports domain-specific model fine-tuning for industry-specific terminology.
- Edge Devices: Perform well on mobile phones and microcomputers where cloud connectivity is limited or unavailable.
Limitations
- Accuracy vs. Newer Models: Vosk's recognition accuracy, while strong, may be slightly behind newer models like Whisper or those using transformer-based architectures.
- Limited Community & Docs: Documentation is functional but not exhaustive, and community support is still growing compared to major frameworks.
- Training Complexity: While it offers training scripts, customizing models from scratch may require deeper knowledge of Kaldi.
- Confidence Scores: Default configurations may not return alternative hypotheses or accurate confidence metrics without tweaking.
- Noise Sensitivity: In very noisy environments, performance may degrade without pre-processing or noise-aware models.
Kaldi is a powerful open-source toolkit designed for speech recognition research. Developed at Johns Hopkins University, it is widely used in academia and industry for building Automatic Speech Recognition (ASR) systems. Kaldi is written in C++ and uses Finite State Transducers (FSTs) to manage the flow of data and models.
Kaldi supports a wide variety of speech processing tasks, including acoustic model training, feature extraction, decoding, and speaker identification. Although originally developed for English, it has been adapted for many languages, including Dutch (Kaldi-NL), Spanish, Arabic, Kannada, and others.
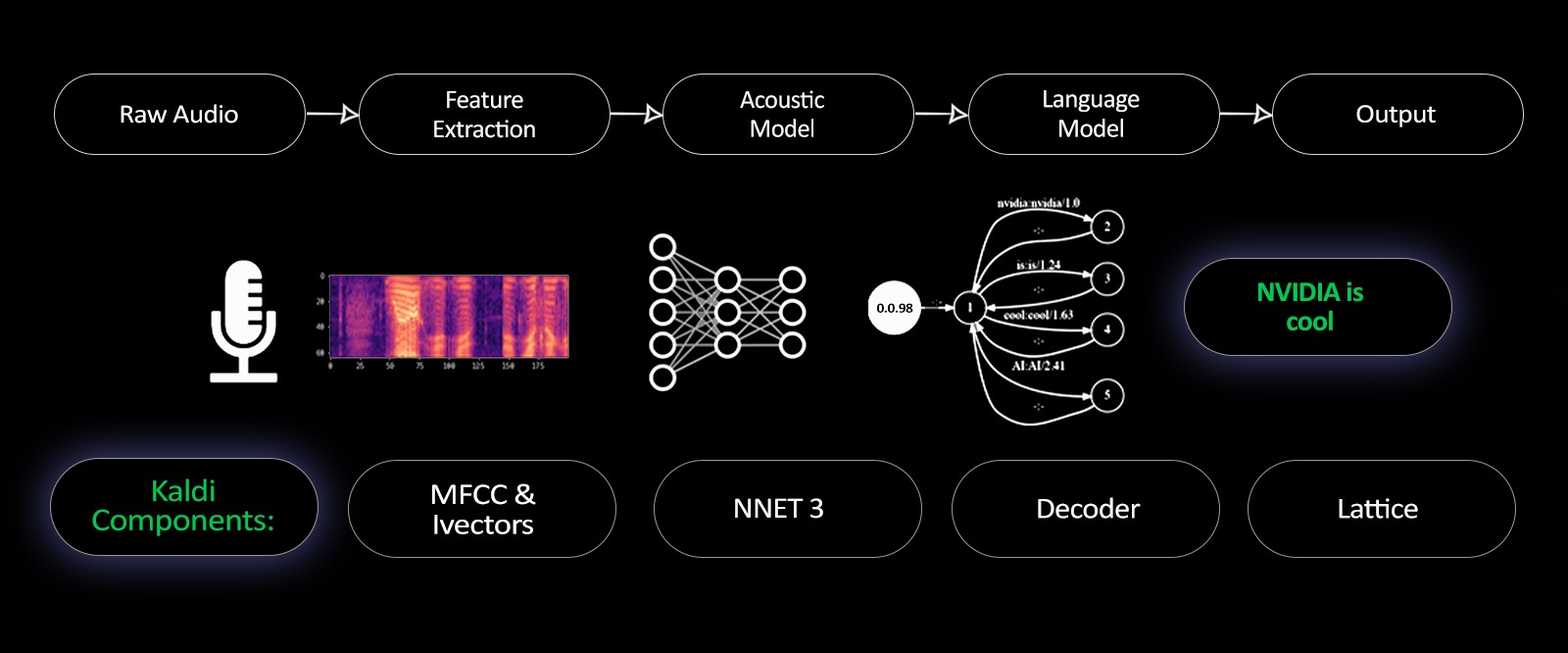
Source: Nvidia
Features
- Flexible Architecture: Uses FST-based workflows, which allow great control over training and decoding pipelines.
- Acoustic Modeling: Supports state-of-the-art models like GMM-HMM, TDNNs (Time Delay Neural Networks), and i-vector/x-vector features for speaker recognition.
- Language Support: Can be customized for multiple languages using different corpora and lexicons.
- Scripted Workflows: Comes with ready-to-use "recipes" for standard datasets (e.g., Wall Street Journal, LibriSpeech).
- Rich Feature Extraction: Extracts MFCCs, deltas, pitch, CMVN (mean and variance normalization), iVectors, and more.
- Lattice-based Decoding: Efficient decoding with beam search and lattice rescoring.
- Speaker Diarization and Verification: Useful for tasks beyond transcription.
- Community Support: Backed by an active research community and updated documentation.
Use Cases
- ASR Model Training: Build custom models for various languages and domains using your own audio datasets.
- Speaker Verification: Used in biometric voice recognition and diarization systems.
- Digits-in-Noise Testing: Automated speech-based hearing screening using Kaldi-NL.
- Clinical Applications: Applied in medical and audiology tests to analyze speech response accuracy.
- Multilingual Research: Ideal for experimenting with different languages and accents using custom corpora.
Limitations
- Steep Learning Curve: Designed for researchers, it requires familiarity with Linux, scripting, and machine learning.
- Installation Complexity: Difficult to install with GPU support; requires dependencies like OpenFST, ATLAS, or Intel MKL.
- No GUI: Entirely command-line based; beginners may find it overwhelming.
- Manual Data Preparation: Requires extensive pre-processing (transcripts, lexicons, language models) before training.
- Limited Real-Time Use: Primarily designed for batch processing rather than live streaming or real-time applications.
Whisper is a versatile ASR model developed by OpenAI. It can transcribe, translate, and generate subtitles in multiple languages. Whisper operates with several pre-configured models (ranging from tiny to large-v2), allowing users to balance speed vs. accuracy based on their needs. It is ideal for general-purpose transcription but can require substantial computational resources for larger models..
Built using whisper.cpp (a C++ port of Whisper), the backend is written in Go, and the frontend uses Svelte and Tailwind CSS. It can run entirely on CPU and supports Docker-based installation for easy deployment.
Below is a sample of how you can use Whisper in real time.
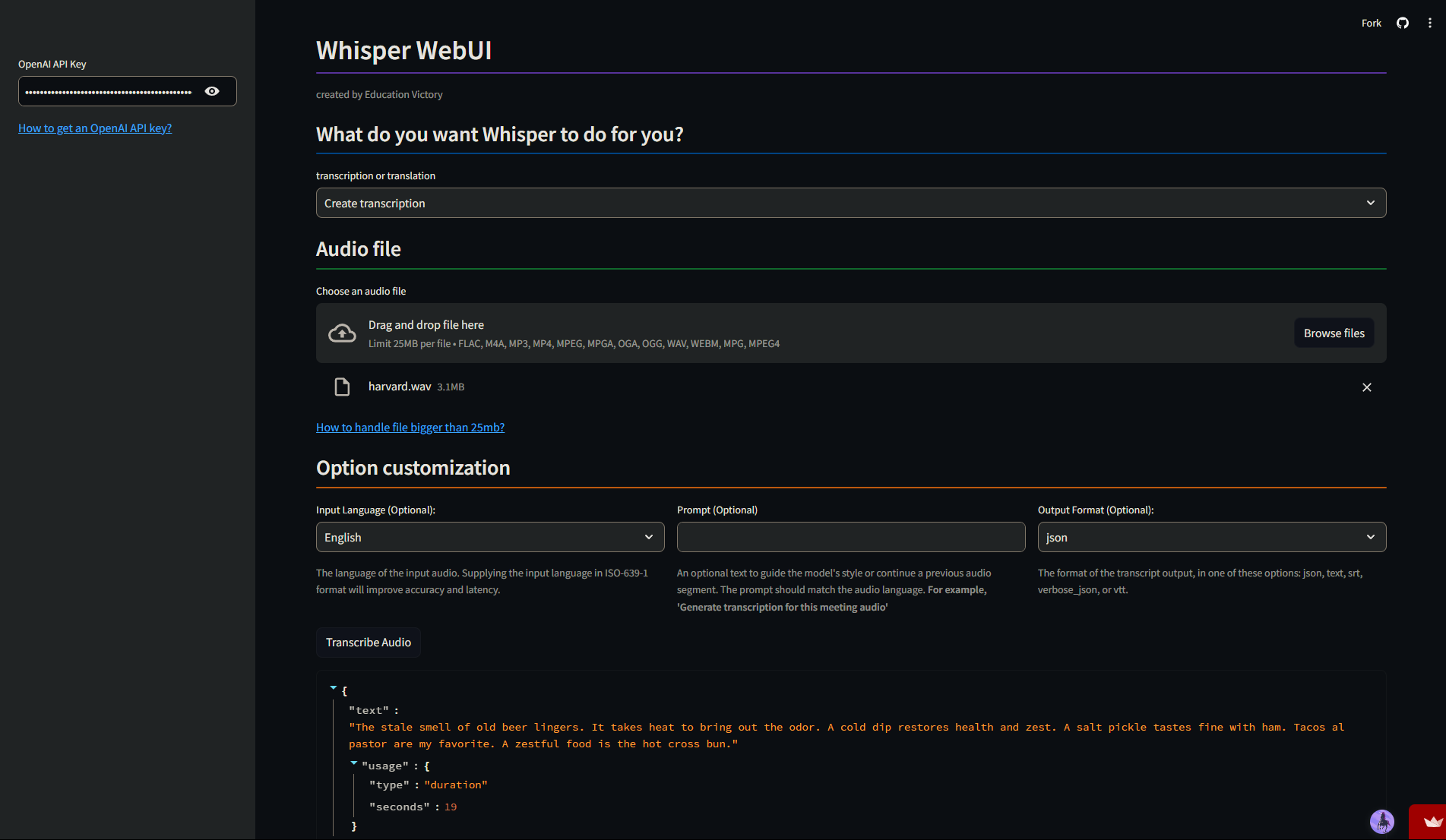
Features
- Web-Based Interface: Transcribe and translate audio directly from your browser.
- File Upload & Mic Input: Supports audio/video uploads or real-time speech via microphone.
- Multilingual Support: Recognises and translates multiple languages into English.
- Model Selection: Choose from different Whisper models (tiny, base, small, medium, large-v2) for speed vs. accuracy.
- Real-Time Transcription: Record, pause, trim, and transcribe live audio input.
- Subtitle Generation: Export in
.SRT,.TXT, and.WebVTTformats. - Text-to-Text Translation: Upload subtitle files (SRT) and translate them across languages.
- Self-Hosting: Fully local processing with Docker Compose; no cloud upload.
- Privacy-First: Audio files are deleted immediately after processing; no third-party servers are involved.
- GPU Optional: Works on CPU; GPU (e.g., NVIDIA) can be used for better performance.
- Extensible: Add models from Hugging Face (e.g., faster-whisper) for advanced customization.
Use Cases
- Content Creators: Generate subtitles and transcripts for videos, podcasts, and tutorials.
- Multilingual Projects: Translate interviews, lectures, or meetings across languages.
- Real-Time Accessibility: Provide live speech-to-text transcriptions for presentations or events.
- Researchers & Developers: Self-host and experiment with Whisper models without vendor lock-in.
- Privacy-Sensitive Users: Use offline transcription without sharing data with third-party APIs.
- Educational Use: Transcribe classroom lectures or translate academic content for accessibility.
Limitations
- No Built-In Security: Lacks authentication or access control; exposing it publicly may pose risks.
- Browser Mic Input Requires HTTPS: Needs a secure connection (e.g., localhost over HTTPS or via reverse proxy like Cloudflare Tunnel).
- Requires Manual Deployment: While Docker simplifies setup, some technical knowledge is still needed.
- Not for Mobile Browsers: Optimized for desktop use; real-time mic input may not function optimally on mobile devices.
- No Automatic Updates: Updates must be manually pulled from GitHub.
- Limited Language Translation Options: Uses built-in models; advanced API-based translation (e.g., DeepL) is not supported out of the box.
DeepSpeech is an open-source speech-to-text engine originally developed by Mozilla, inspired by Baidu’s Deep Speech research paper. It uses a deep learning model implemented in TensorFlow and provides both pre-trained English models and tools for training custom models. DeepSpeech supports end-to-end speech recognition, where audio is directly converted to text without intermediate phoneme models.
Features
- End-to-End Model: Direct audio-to-text transcription using deep neural networks.
- Pre-trained English Models: Ready-to-use models available for immediate deployment.
- Custom Training: Supports training on your own dataset or fine-tuning existing models.
- Language Model Integration: Includes
.pbmmmodel file and.scorerfor improved accuracy. - Multi-language Support: Through community contributions and custom training.
- Offline Capability: Runs locally on devices like Raspberry Pi or powerful GPUs.
- Wrappers Available: Python, Java, JavaScript, C, and .NET for easy integration.
Use Cases
- Offline Speech-to-Text: Useful where privacy or no internet is a concern.
- Voice Assistants: Custom wake word detection and commands.
- Transcription Services: For audio and video content.
- Embedded Systems: On-device STT for IoT and Raspberry Pi.
- Custom Domain-Specific Models: Healthcare, agriculture, or technical fields.
Limitations
- Discontinued Official Development: Mozilla no longer actively maintains it.
- Requires Technical Expertise: Needs coding skills for integration and model training.
- Limited Accuracy vs. Modern Models: Performance may lag behind Whisper or proprietary APIs.
- Audio Restrictions: Works best with 16kHz mono WAV files.
- Resource Intensive for Training: Requires significant GPU power for building custom models.
WhisperX is an advanced extension of OpenAI’s Whisper Automatic Speech Recognition (ASR) model. It builds upon Whisper by introducing enhanced features such as up to 70x real-time transcription speeds, word-level timestamps, and speaker diarization. While Whisper delivers high-quality transcription, WhisperX significantly boosts performance, making it ideal for high-speed, large-scale transcription tasks, particularly in media, academic, and compliance use cases. By combining ASR with wav2vec2 alignment for precise timing and integrating pyannote-audio for multi-speaker recognition, WhisperX offers a robust and efficient solution for detailed audio-to-text processing.
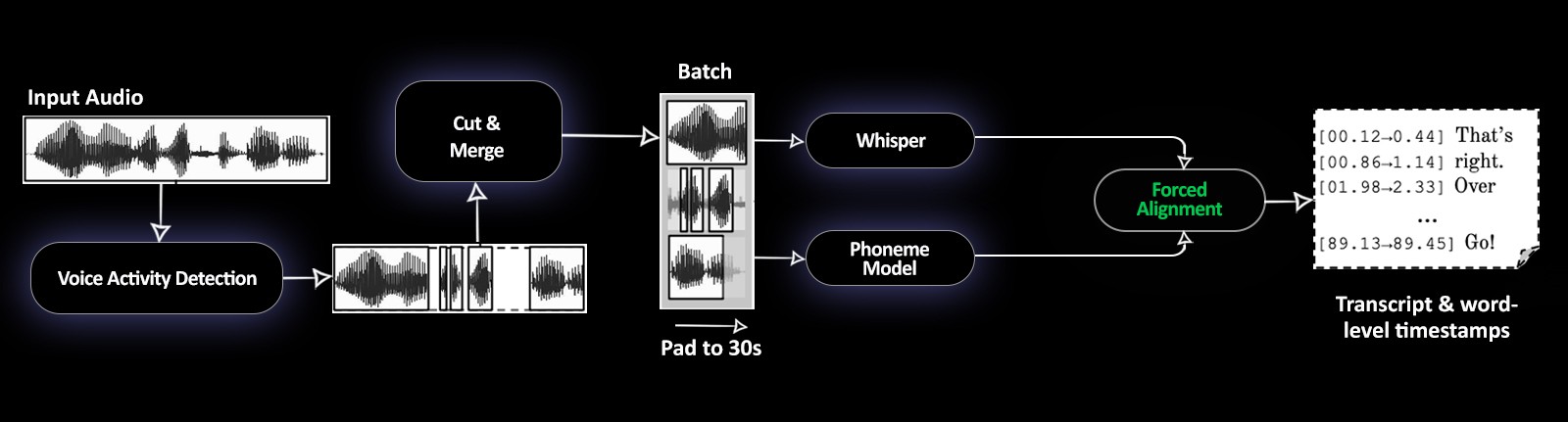
Source: https://github.com/m-bain/whisperX
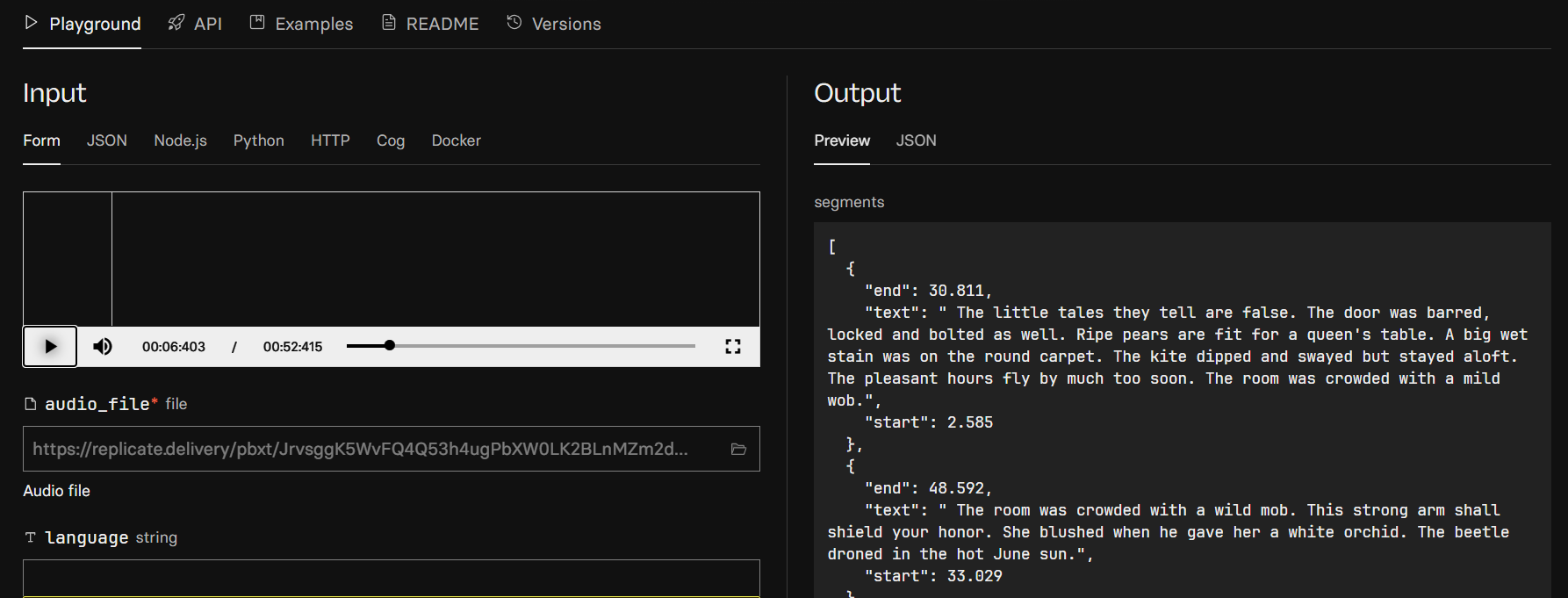
Below is a sample of how you can use WhisperX in real time.
Features
- Extreme Speed: Up to 70x faster than real-time using batched inference with large-v2 model..
- Accurate Word-Level Timestamps: Achieved via wav2sec2-based forced alignment.
- Specker Diarization: Identifies and separates multiple speakers using pyannote-audio.
- VAD Preprocessing: Voice Activity Detection reduces hallucinations without degrading accuracy.
- Lightweight GPU Requirement: Works on GPUs with <8GB memory (for large-v2 at beam_size=5).
- Batched Inference: Highly efficient for bulk or long audio processing.
- Open Source & Research-Backed: Accepted at INTERSPEECH 2023 and ranked 1st in Ego4D transcription challenge.
- Multiple Installation Options: Simple PyPI installation or advanced developer setup.
- Compatible with Faster-Whisper: Optimized backend for speed and low resource usage.
Use Cases
- Media & Broadcast: Transcribe interviews, podcasts, or TV shows with multiple speakers.
- Academic Research: Analyze discussions, focus groups, or long lectures requiring precise timestamps.
- Legal & Compliance: Detailed meeting notes with diarization for speaker accountability.
- Healthcare: Medical consultations where speaker attribution and accuracy are critical.
- AI Training Data: Generate high-quality, aligned transcripts for model training.
- Subtitling & Captioning: Create accurate subtitles with sentence-level segmentation and timing.
Limitations
- Complex Setup for Advanced Features: Speaker diarization requires Hugging Face token and extra dependencies.
- Not Perfect for Overlapping Speech: Handling multiple simultaneous speakers is limited.
- Alignment Restrictions: Words with symbols (e.g., “£13.60”, “2014.”) may not align correctly.
- Language Dependency: Requires language-specific wav2vec2models for alignment.
- GPU Dependency for Best Performance: It does have a CPU mode. However, Speed and batching will require a GPU with CUDA/cuDNN installed.
- Dependency Conflicts: Known issues with pyannote-audio and faster-whisper versions.
| Feature | Amical | Vosk | Kaldi | Whisper | DeepSpeech | WhisperX |
|---|---|---|---|---|---|---|
| Open Source | Yes | Yes | Yes | Yes | Yes | Yes |
| Platform | Windows, Mac | Windows, Linux, Android, iOS, Raspberry Pi | Linux (Windows with WSL) | Browser (Self-host), Linux, Windows | Windows, Linux, Raspberry Pi | Linux, Windows |
| Dictation app | Yes | No | No | No | No | No |
| Push to talk | Yes | No | No | No | No | No |
| Offline Support | Yes (Local Models) | Yes | Yes | Yes (Local Deployment) | Yes | Partial (Needs GPU for best performance) |
| Cloud Support | Yes (Optional, BYO API) | No | No | No | No | Yes (Optional) |
| Bring Your Own API Key | Planned | No | No | No | No | Yes (Hugging Face for diarization) |
| Language Support | Multi-language | 20+ languages | Multi-language (custom corpora) | Multi-language | English (others via custom training) | Multi-language |
| Real-Time Transcription | Yes | Yes | Limited | Yes | Yes | Yes |
| Voice Activity Detection (VAD) | Yes | Yes | Yes | Yes | No | Yes |
| Speaker Diarization | Planned | No | Yes (custom setup) | No | No | Yes |
| Custom Vocabulary | Yes | Yes | Yes | No | Yes | No |
| AI Transformations (Grammar, Translation) | Yes | No | No | No | No | No |
| Ease of Setup | ⭐⭐⭐⭐ (Simple UI) | ⭐⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Performance (Speed) | High | High (lightweight models) | High (batch processing) | Moderate | Moderate | Very High (70x real-time) |
| Accuracy | High | Good (slightly behind the transformers) | Very High (custom models) | High | Moderate | Very High |
| Cost | Free + optional API cost | Free | Free | Free | Free | Free |
| Best For | Productivity & Note-Taking. Best transcription software for writers. | Developers & Offline Apps | Research & ASR Training | Web Users & Privacy-Conscious | Offline Simple STT | Large-Scale, Fast, Multi-Speaker Transcription |
Why Amical is the Best Local and Open Source Alternative to Transcription Apps in 2025
Many open-source tools like Whisper or Vosk are excellent transcription models but require technical setup to use. Amical bridges this gap by packaging these models into a user-friendly desktop app for Mac and Windows, enabling instant dictation and meeting transcription without coding or configuration.
Built for Privacy-First Users
Amical is designed for individuals and organizations that value data security and confidentiality. Unlike cloud-only solutions, it allows you to run AI models entirely on your local machine. This ensures that sensitive conversations, such as board meetings, legal discussions, or personal notes, never leave your device.
Open Source & Fully Transparent
As an MIT-licensed open-source project, Amical promotes transparency and community-driven innovation. Anyone can review the code, contribute features, or customize it to their specific workflow. This eliminates vendor lock-in, giving users full control over their transcription setup.
Cloud + Local Flexibility
Not everyone needs to stay completely offline. Amical offers the best of both worlds by allowing users to switch between local models for privacy and cloud models for speed and accuracy. This flexibility makes it ideal for businesses, creators, and developers who want to optimize performance without sacrificing security.
Intelligent Transcription with Context-Aware Formatting
What sets Amical apart among all the open-source transcription apps is its context-awareness. The software intelligently detects the platform you’re using, be it Gmail, Slack, Instagram, or Notion, and formats the text accordingly. Writing an email? Expect a professional tone and structure. Drafting a social post? It automatically adds the right emojis and casual phrasing.
AI-Powered Note-Taking & Meeting Transcription
Amical isn’t just a transcription app. It’s a complete productivity assistant. Users can take quick notes via voice or record and transcribe meetings in real time. Planned features include system audio capture for online meetings, making it a strong alternative to expensive SaaS transcription tools.
Custom Vocabulary & Voice Shortcuts
Add industry-specific jargon or brand names to Amical’s custom vocabulary for unmatched transcription accuracy. Additionally, create voice shortcuts to trigger actions such as opening apps, sending messages, or formatting text, all powered by MCP (Model Context Protocol) integration. Therefore, it can be considered one of the best transcription software for writers.
Conclusion
Open-source transcription software in 2025 is redefining productivity with unmatched flexibility, privacy-first design, and zero licensing costs. Whether you’re a creator, a business professional, or a developer, there’s a solution tailored to your needs.
It is important to choose the best one without wasting much time. This guide helps you find the best open-source transcription software available online. Among all of them, Amical serves as one of the best transcription software for writers. However, your preferred transcription software can vary as per your use case. If offline functionality and lightweight performance are your top priorities, Vosk is a solid choice, whereas Kaldi caters to researchers who need full control over ASR pipelines. For an intuitive web-based experience, Whisper is ideal, while DeepSpeech is suited for simple offline setups.
Transcription software has become increasingly essential in today’s fast-paced world, and its use is expected to continue rising. The flexibility and cost-effectiveness of open-source transcription tools provide users with unprecedented control over their transcription needs, whether for privacy, customization, or seamless integration. Choose the tool that best suits your requirements, whether it's speed, accuracy, offline functionality, or ease of integration.
FAQs
-
How is Amical different from Whisper, Vosk, etc.?
Amical is not just a speech-to-text model; it’s a full-fledged desktop application for Mac and Windows. While Whisper and Vosk are AI models you can run locally, Amical integrates them into an easy-to-use app that provides dictation and meeting transcription at the push of a button.
-
How does Whisper compare to other open-source transcription tools like Vosk and Kaldi?
Whisper offers high-quality transcription with multi-language support and can handle real-time transcription effectively. While Vosk is ideal for offline use and low-resource devices, Kaldi is more suited for researchers who need deep customization and control over ASR models.
-
Can I use Whisper for offline transcription?
Yes, Whisper can be used offline if you host it locally. By self-hosting the model, you can transcribe audio without an internet connection, ensuring privacy and security.
-
Is Vosk suitable for real-time transcription?
Yes, Vosk supports real-time transcription with a streaming API. It’s particularly useful for low-power devices, offering accurate results without the need for internet connectivity.
-
What are the key differences between Kaldi and Whisper for speech recognition?
Kaldi is a toolkit best suited for research and development, offering extensive customization options, while Whisper is a more user-friendly solution that focuses on high-quality, real-time transcription with less configuration required. Kaldi is ideal for specialized tasks, whereas Whisper excels in general-purpose transcription.